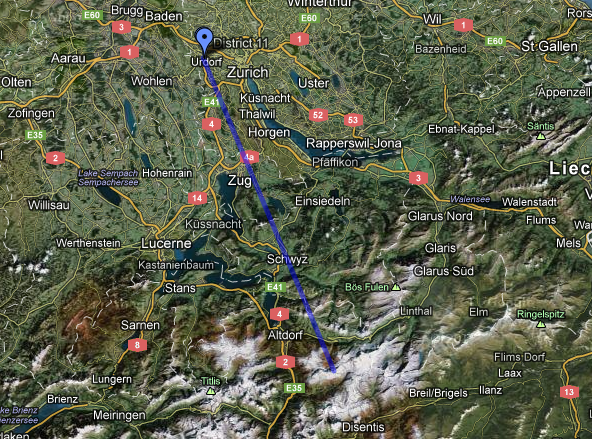
So we did it again, we celebrated Greg’s, Maciej’s, and Bogdan’s recent successes with a barbecue. But we were not SPCL if it was any barbecue … of course it was at the top of a mountain, this time the “Grosse Mythen”.
Remember v1.0 to Mount Rigi? Switzerland is absolutely awesome! Mountains, everything is green, ETH :-).
Here are some impressions:
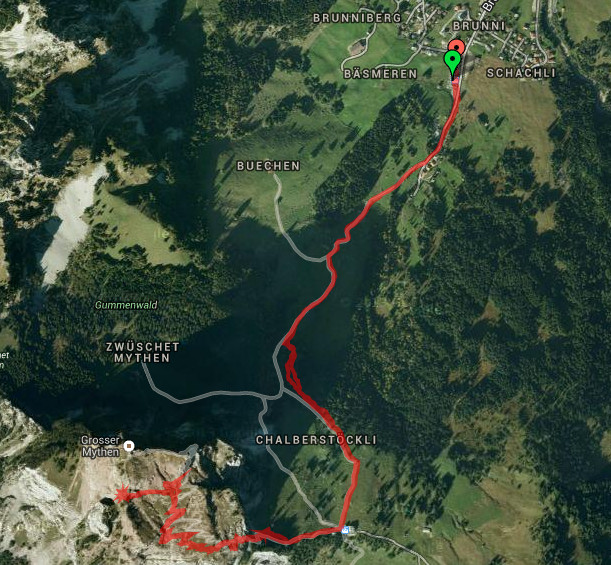
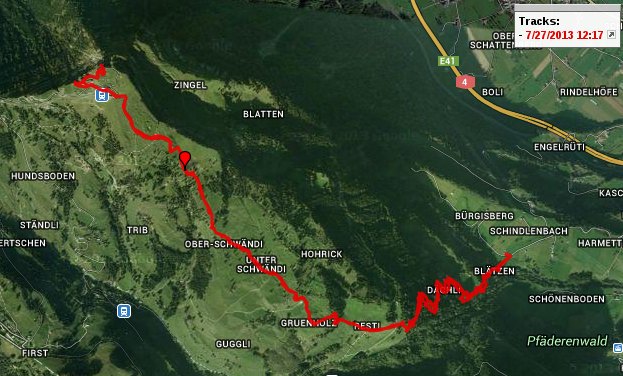
The complete tour was 6.9 kms a total walking time of 3.35 hours and an altitude difference of only 750m (from 1149m to 1899m). Much shorter and less altitude then our last trip. But not less fun! And yes, my GPS was a bit off :-/.

So this is how it looked from the start — I have to say pretty impressive. But it turned out to be much much simpler than it seems, and MUCH simpler than Rigi was :-).

Do you see the flag on top (yeah, it’s the red pixel on the right side in this resolution)? That’s where we’ll hike!

Our first real view towards Brunni.

The path is actually at the beginning a bit more stressful than later but overall simple.

It still seems impressive!

Lots of planes around Mythen, some seem rather historic, like this one.

First stage done — arrived at Holzegg and view down to Brunni (yeah, we could have taken the cable car but are we men or what?). SPCLers walk up mountains!

Now the steep part begins, it’s actually a bit dangerous — many places where you can fall a couple of 100 meters :-).

Mac still looks too good … we should have taken more water and food :-). Remember Rigi?

Nice views and deep abysses.

The path is basically vertically (in serpentines) up a rock wall. Nice! You should not be afraid of height …

… because you will constantly see beautiful things like this …

… or this …

… or horror abysses right at the trail like this :-).

But there were helpers, these nice chains probably saved out life more than once.

Mac acquired a second backpack and some stones on the way … and he’s still looking too good!

A nice bench … again, for people not afraid of height.

The chains at the abyss :-).

The neighboring “Kleiner Mythen” is apparently much harder to climb. And it’s smaller, so why would we climb it anyway!? 😉

The path – awesome! Walking a nice and thin ridge.

And again, some nice opportunities to fly, aehem fall.

Still snow around the top in May.

Finally, the top.

The top – we made it! Most importantly: the Swiss flag :-).

Beautiful views …

The last ascent to the very top … still looking too fresh!

Beautiful.

We all made it to the top alive (and later back down).

Nice weather actually.

Relaxing with a beer … tststs.

More beer!?

Meanwhile food preparations start.

The grill didn’t start that well … we should have sent smoke signals down to the valley ;-).

Some folks took shifts in blowing.

We brought some nice food … to the nice view!

And ate it quickly ;-).

To avoid fights with the locals!

Finally the grill started … took 30 mins or so ;-).

Too much food!

Beautiful views, did I mention that it was rather high?

But most beautiful views — Rigi was just left of this.

And of course, if you travel with a Polak, you’ll get some top-vodka.

The car was waiting patently in Brunni.

On the way back down.

Many opportunities for free falls :-).

And beautiful alpine flowers.

I drove, and we made some contact with cows :-).

Others took the bus back home.
After all, *awesome* and very efficient, the whole tour took 7.5 hours :-). So we set some new standards for the SPCL hike v 3.0!