| Home -> Research -> cDAG | ||||||||||||||||||||||||
Home

Events 



 Past Events 





|
cDAG - A Framework for the Runtime Detection and Optimization of Collective Communication PatternscDAGA Framework for the Runtime Detection and Optimization of Collective Communication PatternsThere are several reasons why users of parallel programming APIs might express collective communication patterns with point-to-point operations:
Using point to point operations instead of collectives hurts the performance portability of the code - the optimal communication pattern heavily depends on machine parameters, such as network topology, network latency, bandwidth and injection rate. The cDAG technique expresses collective communication patterns as dependency graphs, where the vertices represent operations (send, recv, calculations) and the edges express the dependencies between those operations. The translation to this formulation is simple in most cases (but not automated yet).
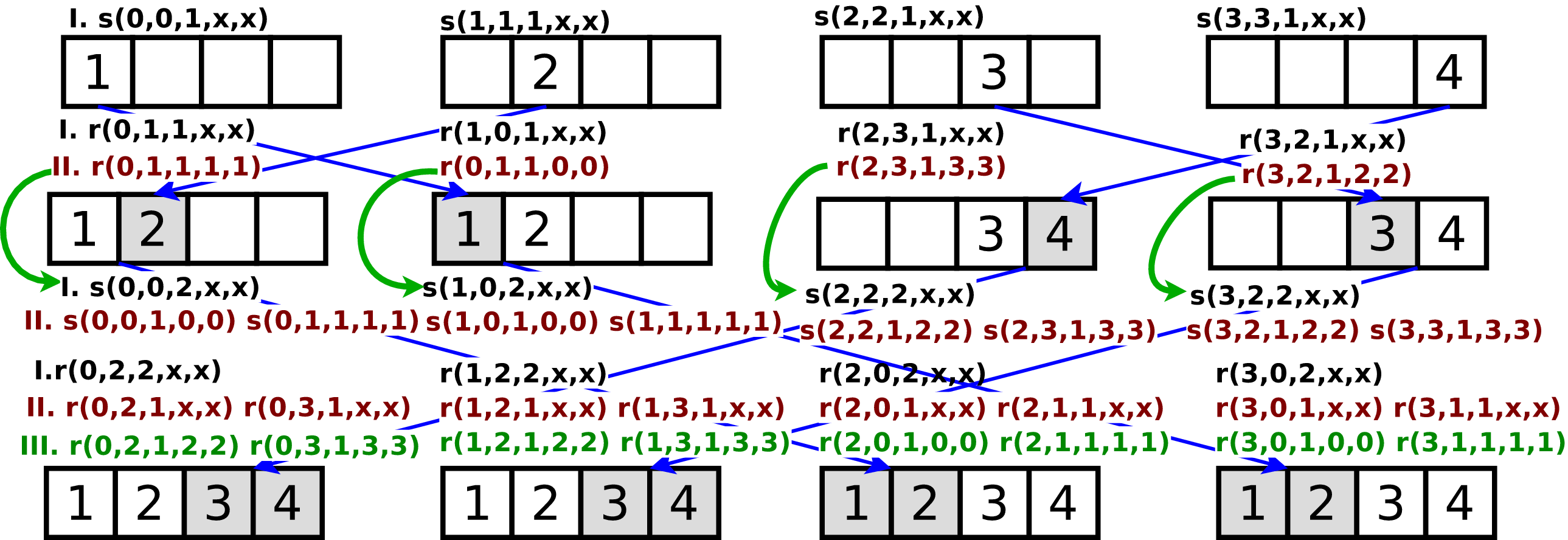
In the cDAG_Compile() function we collect all process local communication graphs and transform them into a single global communication graph, with a new kind of edges which express which send operation matches which receive operation, in addition to the dependency edges. Each vertex in this graph is represented by a Single Static Transfer tuple if the form type(destination-rank, address of destination buffer, data size, source rank, address of source buffer), where type is either send or rreceive Of course not all values are known for each tuple in the beginning, for example in an receive operation, we do not directly know the address of the source buffer. However, this knowledge can be obtained by traversing the data-flow graph. If a process receives a large chunk of data and sends one half of the data to a different process than the other half, the SST tuples are also split in two, as if the data had originally been received in two parts. This procedure allows us to express the data-flow of any communication operation. Please consult the references for details of the algorithm.
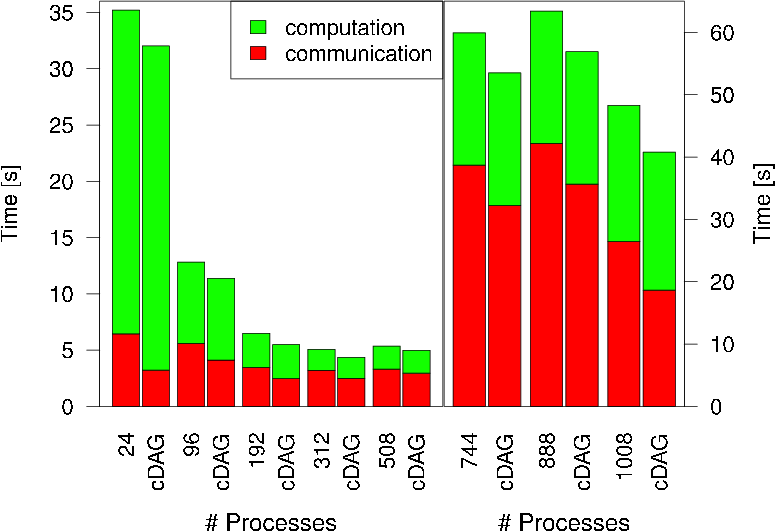
After the data-flow is solved, we know the communication semantics (which data item is communicated from where to where) of the communication graph, if we look at the SST tuples. For example the tuple r(0,1,1,1,1) tells us that process zero receives one byte of data into address one, which comes from rank one and was stored that at address one. Each of the data-movement collectives defined by MPI (and possibly other) can be identified by the form of the SST tuples which result from any (pipelined, tree-based, etc.) implementation of such a collective. Therefore we can check if the SST tuples observed fall in any of the predefined categories, and if yes, substitute their execution with a call to the appropriate MPI (or any other tuned collective implementation) function. Below we show the performance improvement of the UPC version of the NAS FT benchmark code if we apply our approach (left bar in each group is the original code, the right bar represents the modified version which uses cDAG):
The cDAG library can be downloaded here. References
| |||||||||||||||||||||||



| serving: 216.73.216.13:31326 | © Torsten Hoefler |