| Home -> sparsity-in-dl | ||||||
Home

Events 



 Past Events 





|
Sparsity in Deep Learning TutorialSparsity in Deep Learning
Title: Sparsity in Deep Learning
Recording: Will be available on YouTube Key aspects used in this tutorial are included in our paper, Sparsity in Deep Learning: Pruning and growth for efficient inference and training in neural networks [1], available on arXiv. Abstract: The growing energy and performance costs of deep learning have driven the community to reduce the size of neural networks by selectively pruning components. Similarly to their biological counterparts, sparse networks generalize just as well, if not better than, the original dense networks. Sparsity can reduce the memory footprint of regular networks to fit mobile devices, as well as shorten training time for ever growing networks. In this paper, we survey prior work on sparsity in deep learning and provide an extensive tutorial of sparsification for both inference and training. We describe approaches to remove and add elements of neural networks, different training strategies to achieve model sparsity, and mechanisms to exploit sparsity in practice. Our work distills ideas from more than 300 research papers and provides guidance to practitioners who wish to utilize sparsity today, as well as to researchers whose goal is to push the frontier forward. We include the necessary background on mathematical methods in sparsification, describe phenomena such as early structure adaptation, the intricate relations between sparsity and the training process, and show techniques for achieving acceleration on real hardware. We also define a metric of pruned parameter efficiency that could serve as a baseline for comparison of different sparse networks. We close by speculating on how sparsity can improve future workloads and outline major open problems in the field. 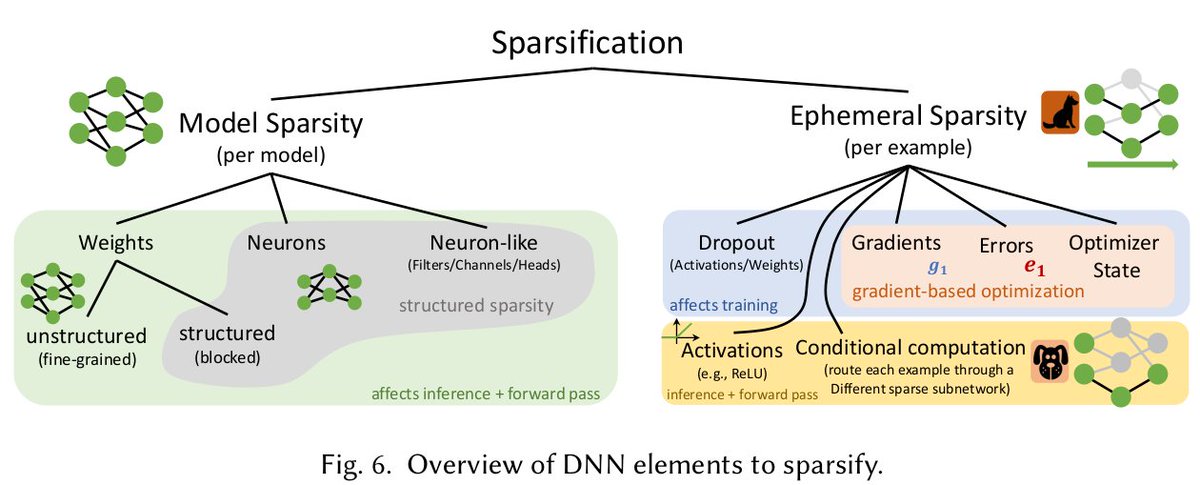 Iterations ICML'21
Venue: The Thirty-eighth International Conference on Machine Learning [ICML'21] Content This tutorial will perform an detailed overview of the work on sparsity in deep learning, covering sparsifi- cation techniques for neural networks, from both the mathematical and implementation perspectives. We specifically aim to cover the significant recent advances in the area, and put them in the context of the foundational work performed on this topic in the 1990s. The context for the tutorial is provided by the growing energy and performance costs of deep learning, which have driven the community to research ways of reducing the size of neural networks. One of the most popular approaches is to selectively prune away components. Similarly to their biological counterparts, sparse neural networks have been found to work just as well, if not better than, the original dense networks. In practice, sparsity can reduce the memory footprint of regular networks to fit mobile devices, as well as shorten training and inference times. We will describe the “natural” emergence of sparsity in deep neural network components, as well as techniques to remove and add elements of neural networks, different training strategies to achieve model sparsity, and mechanisms to exploit sparsity in practice. This tutorial accompanies a recent survey that the presenters have co-authored on the topic, which distills ideas from more than 300 research papers published over four decades, and provides guidance to practitioners who wish to utilize sparsity today, as well as to researchers whose goal is to push the frontier forward. The tutorial is based on a comprehensive overview paper of the field [1]. More precisely, we will cover the following topics. 1. What can be pruned? The first question is which elements of a neural network can be removed. Here, we cover literature proposing model or structural sparsification, e.g., zeroing weights, but also ephemeral sparsification, e.g. sparsification of gradients and activations. The figure above provides a graphical overview of elements which can be pruned. 2. How to prune? We cover all the general pruning approaches—from classic ones such as magni- tude pruning, to second-order approaches, and regularization and variational approaches. We will specifically emphasize the mathematical justification for each such general approach, and provide context in terms of computational and implementation cost. 3. What is known? There has been extremely significant early work on sparsity, in e.g. the 90s, which introduced several fundamental concepts and techniques. Unfortunately, many of these concepts have been re-invented in recent years. Our tutorial will provide a holistic view of these results, integrating both the early work, as well as recent advances. 4. Metrics and Results. Further, our tutorial investigates key metrics in this area, such as the efficiency of different types of pruned models relative to the remaining number of parameters, and performs an in-depth comparison of the performance of various sparsification techniques on standard tasks such as image classification and natural language processing. 5. Outlook and Challenges. We end with an overview of the current state of the area, focusing on under-explored topics. Specifically, we outline ten major challenges for research in the area. Goals and Target Audience Sparsity has become a very active research topic recently, leading to several fascinating research threads, from investigations on the "lottery ticket hypothesis," to efficient numerical meth- ods and sparsity-aware software and hardware designs. Our major goal is to provide a concise but coherent snapshot of the area, with the following sub-goals: (a) Community Building: We aim to highlight the significant progress made by such methods recently, and highlight the impact on related areas, such as efficient inference and training for neural networks.(b) Emerging Benchmarks and Reproducibility: In our view, one current issue in this area is the relative lack of common benchmarks, which can lead to incomplete comparisons and work duplication. We aim to highlight a few tasks which are emerging as natural benchmarks, and discuss the performance of state-of-the-art methods on these benchmarks. (c) Fostering Collaboration: By discussing the myriad different approaches which have been pro- posed for pruning in a common framework, we believe that the tutorial will help “cross-pollination” between sub-areas. Moreover, both speakers are academics with significant industrial involvement, and the tutorial will highlight the potential practical impact of such methods, particularly focusing on natural “contact points” between academia and industry. The tutorial is targeted at academics, researchers in industry, and engineers interested in software and hardware design. The tutorial is specifically-designed to be self-contained, and will be accessible to a wide audience. More precisely, our tutorial aims to bridge the gap between researchers working on theoretical and algorithmic aspects of deep learning, and practitioners interested in leveraging sparsity for practical gains. We aim to achieve this by carefully covering both the mathematical underpinnings of pruning methods, as well as the technical methods for leveraging sparsity in practice.
| |||||



| serving: 216.73.217.111:7509 | © Torsten Hoefler |